是一種機器學習方法,強調 智能體(Agent) 如何基於環境而行動,取得最大化的預期利益。簡單來說,讓一個AI在不斷嘗試錯誤的過程中,學習到什麼樣的行為能帶來最好的結果
智能體(Agent): 進行決策的主體,例如:下棋程式、機器人環境(Environment): 智能體所處的環境,會根據智能體的行動給予回饋狀態(State): 環境在某個時間點的狀態行動(Action): 智能體可以採取的動作獎勵(Reward): 環境給予智能體的回饋,正向獎勵表示行動是好的,負向獎勵表示行動是壞的策略(Policy): 智能體根據狀態選擇行動的規則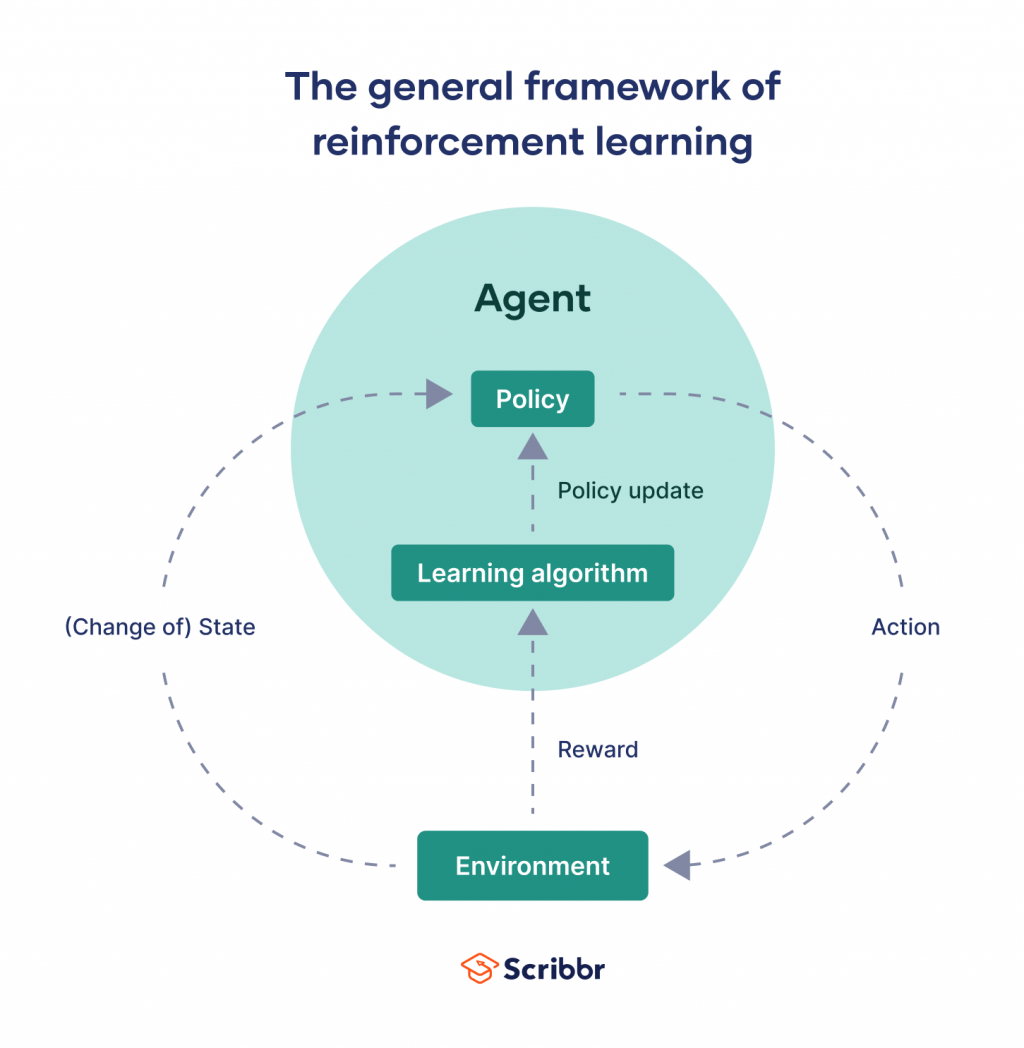
初始化:設定初始狀態、行動空間、獎勵函數探索與利用:智能體在環境中探索,嘗試不同的行動,並根據得到的獎勵更新策略學習:智能體不斷重複探索與利用的過程,逐漸學習到最佳的策略遊戲:AlphaGo、Atari遊戲機器人控制:自主駕駛、機器人行走金融:股票交易、風險管理推薦系統:商品推薦、內容推薦
G_t = ∑_{k=0}^{∞} γ^k * r_{t+k}
G_t |
從時間步t開始的累積折扣獎勵 |
|---|---|
γ |
折扣因子,平衡當前獎勵和未來獎勵重要性 |
r_{t+k} |
時間步t+k得到的獎勵 |
Q-learning: 值函數演算法,學習狀態-行動對的價值Policy Gradient: 策略演算法,直接學習策略Deep Q-Network (DQN): 將深度學習與Q-learning結合,處理高維度狀態空間import gym
import numpy as np
env = gym.make('CartPole-v1')
observation = env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample() #隨機選擇動作
observation, reward, done, info = env.step(action)
if done:
observation = env.reset()
env.close()


 iThome鐵人賽
iThome鐵人賽